

响指HaiSnap-人人都能创造的AI零代码应用平台
一个通过自然语言对话即可生成完整应用的AI零代码平台。
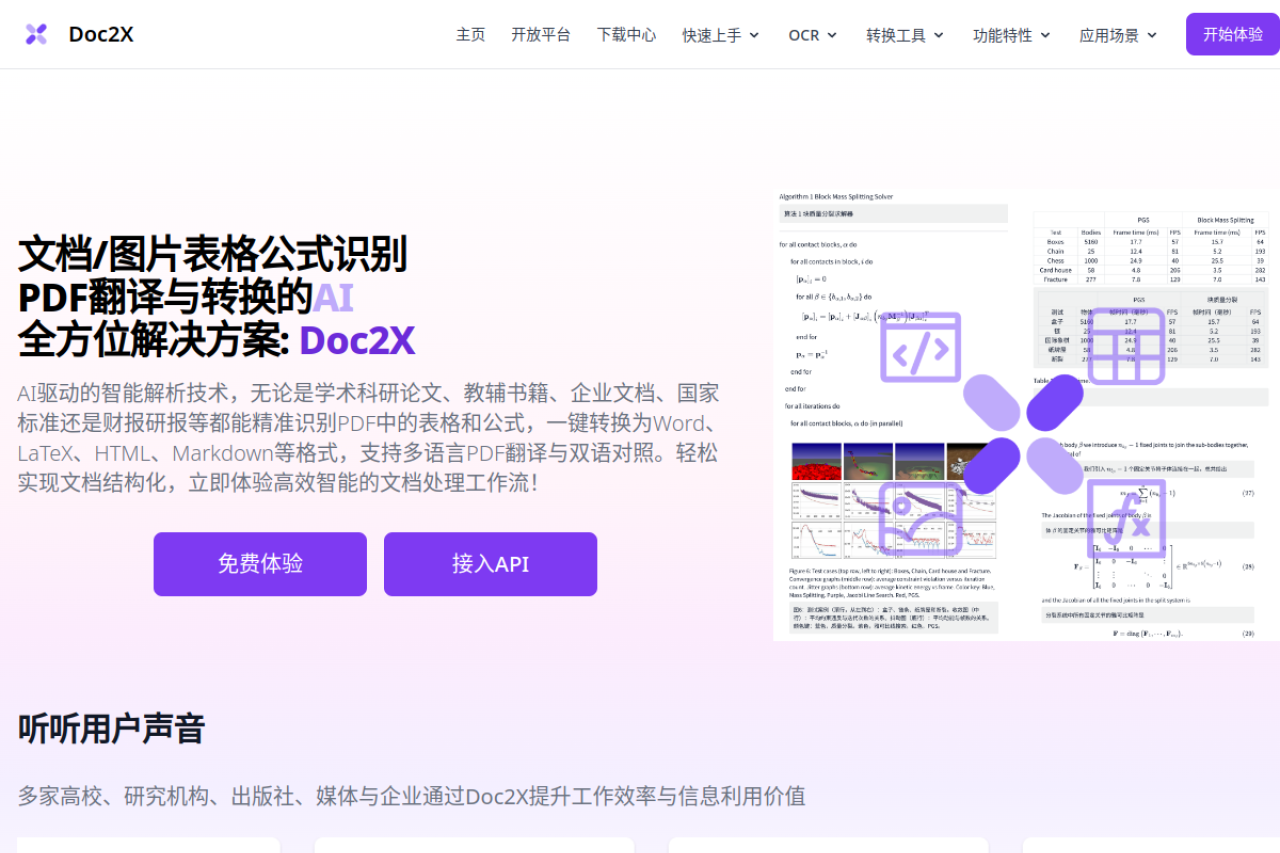
在信息处理日益数字化的今天,如何高效、准确地从各类文档(尤其是包含复杂公式和表格的PDF)中提取并转换信息,是学术、办公及众多行业面临的共同挑战。Doc2X正是应此需求而生的一款AI全方位解决方案。它并非简单的格式转换工具,而是集成了高精度光学字符识别(OCR)、深度学习与大语言模型技术的智能平台,致力于解决传统文档处理中的痛点,为用户打造从识别、转换到翻译的一站式高效工作流。
Doc2X的核心功能在于其卓越的识别与转换能力。用户只需上传PDF文件或图片,系统便能自动完成对文档中文字、表格、特别是复杂数学公式的精准识别。这得益于其搭载的先进AI模型,能够理解并解析各类文档结构。在识别完成后,Doc2X支持将内容一键转换为多种通用格式,包括Word(.docx)、LaTeX、HTML、Markdown等。这种灵活性使得转换后的内容能无缝对接不同的后续应用场景,无论是用于论文写作、报告编辑还是网页发布,都极大提升了文档复用和编辑的便捷性。对于科研人员、学生和编辑而言,这意味着从PDF中提取公式和数据不再需要手动输入,避免了错误,节省了大量时间。
超越基础的识别转换,Doc2X还融入了强大的语言处理能力——多语言翻译功能。这对于处理外文文献、国际标准或跨国业务文档的用户来说是革命性的。平台能够将识别出的内容翻译成指定语言,并创新性地提供“双语对照”阅读模式。用户可以在一个界面中并排查看原文和译文,这对于语言学习、论文研读或跨国团队协作中的信息理解至关重要。结合大模型技术,翻译结果不仅准确,而且能更好地保持原文的专业术语和语境,实现了“识别-转换-翻译”的流程闭环。
Doc2X的应用场景广泛,精准覆盖了多个高需求领域。在学术科研场景中,它是处理论文PDF、教材、技术手册的利器,能快速提取公式、表格供分析和引用。在教育领域,教师可以利用它从各种资料中组建题库和试卷。在金融、法律、工程等行业,面对大量含有数据表格和特定格式的行业报告、财报、合同,Doc2X能高效地将其结构化,便于信息提取与再利用。其用户群体包括但不限于高校师生、研究员、出版社编辑、媒体从业者、企业员工以及任何需要频繁处理文档的个人。从页面展示的用户声音来看,众多高校、研究机构和企业已采用Doc2X来提升工作效率与信息利用价值。
选择Doc2X,用户获得的不仅仅是一个工具,更是一个效率提升的伙伴。它将繁琐、耗时的文档处理工作自动化、智能化,显著降低了人力成本与出错率。通过提供免费的体验入口和灵活的API接入方式,Doc2X既照顾了普通用户的轻量需求,也满足了企业或开发者进行深度集成的需求。对于追求高效、精准文档处理的用户而言,Doc2X代表了以AI技术解决实际生产力问题的优秀实践,是数字化办公与学术研究中不可或缺的智能助手。
本站词点网提供的Doc2X文档图片公式识别/翻译/转换都来源于网络,不保证外部链接的准确性和完整性,同时,对于该外部链接的指向,不由词点网实际控制,在2026年5月5日 上午11:42收录时,该网页上的内容,都属于合规合法,后期网页的内容如出现违规,可以直接联系网站管理员进行删除,词点网不承担任何责任。